Building an Visual Language Model from scratch
My initial aim was to build a document processing model. But the idea was far fetched for my skill at the time. So, I settled down for building a toy version of visual language model for better understanding of VLM. I’m documenting my intuition for the benefit of myself and others. My model will receive image as an input and return its caption as an output. Luckily, I found a dataset with image and it’s caption to train.
Instead of training all the component from scratch, I’m going to use pre existing LLM model and customize to our need. You could ask why did you mention scratch in the title and say the title is
misleading. In general, this is how VLM are built. Correct me if I’m wrong me.
The off the shelf models are:
ViT
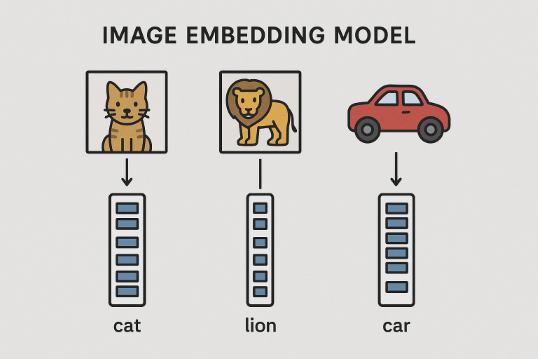
This model is an image embedding model. It returns embedding tensor representation for an image. That means, the vector distance between similar image is shorter. The vector distance between lion and cat will shorter than the vector distance between lion and car. Since, the lion and cat are animals.
GPT2
This model is a text generation model. Given a list of word, it’ll predict the next series of words.
| Input | Output |
|---|---|
The sky is | The sky is blue |
Projection layer.
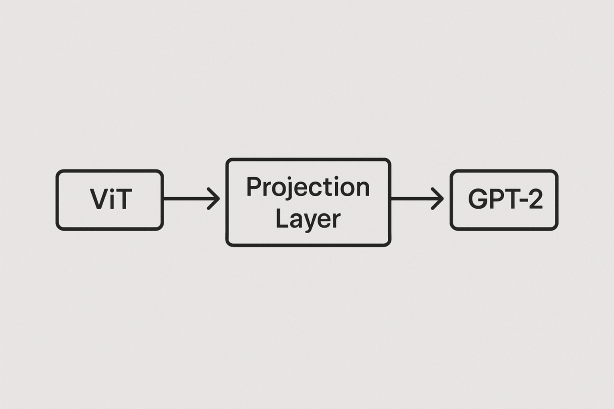
This is the key component of our VLM model. This layer transform the image embedding output into a GPT2 textual embedding space. In other words we are converting the images into an intermediate state for the GPT2 to produce meaningful output.
class Projection(nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.network = nn.Sequential(
nn.Linear(in_features, in_features * 3),
nn.GELU(),
nn.Linear(in_features * 3, out_features),
)
def forward(self, input):
return self.network(input)
The tensor output size of ViT mode is 512 and the tensor input size of gpt2 model is 768. This projection layer will convert the ViT output tensor size into gpt2 input tensor size. With training, the image tensor are transformed into a tensor that GPT2 understands.
self.projection = Projection(512,768)
Conclusion
I’ve put all the component together and trained it with the dataset. Here is the result:
Input Image:

Output Text:
a boy holding a fish in the woods
This project gave me an solid intuition of building a VLM model. In the upcoming days I’m aspiring to build a document processing VLM model that beats state-of-the-art(SOTA) benchmarks. You can see the entire code here